
I am a Staff Research Scientist at Google DeepMind in London, where I co-lead the Gemini video understanding workstream. My research interests lie in efficient audio-visual processing, temporally localized, high frame-rate and long-form video understanding, and leveraging video comprehension for generation — addressing data, modeling, and evaluation on both the pretraining and post-training fronts. These capabilities are used in a variety of Google products, including Project Astra, AI Studio, the Gemini API, YouTube, Google Cloud, the Gemini app, Veo, Omni and Gemini Live. In 2023, I completed my PhD in the WILLOW team of Inria Paris and École Normale Supérieure, advised by Antoine Miech, Josef Sivic, Ivan Laptev and Cordelia Schmid. My thesis, supported by a Google PhD Fellowship, focused on learning visual language models for video understanding. In 2020, I received an engineering degree from École Polytechnique and a MSc degree in Mathematics, Vision and Learning from ENS Paris-Saclay. I previously interned at Huawei Noah's Ark Lab and Google Research Perception. See my LinkedIn profile for a full resume.
News
Research
See my Google Scholar and GitHub profiles for more information.


CVPR 2026
@inproceedings{fiastre2026maskcaptioner,
title={MaskCaptioner: Learning to Jointly Segment and Caption Object Trajectories in Videos},
author={Gabriel Fiastre and Antoine Yang and Cordelia Schmid},
booktitle={CVPR},
year={2026}}
Dense Video Object Captioning (DVOC) is the task of jointly detecting, tracking, and captioning object trajectories in a video, requiring the ability to understand spatio-temporal details and describe them in natural language. Due to the complexity of the task and the high cost associated with manual annotation, previous approaches resort to disjoint training strategies, potentially leading to suboptimal performance. To circumvent this issue, we propose to generate captions about spatio-temporally localized entities leveraging a state-of-the-art VLM. By extending the LVIS and LV-VIS datasets with our synthetic captions (LVISCap and LV-VISCap), we train MaskCaptioner, an end-to-end model capable of jointly detecting, segmenting, tracking and captioning object trajectories. Moreover, with pretraining on LVISCap and LV-VISCap, MaskCaptioner achieves state-of-the-art DVOC results on three existing benchmarks, VidSTG, VLN and BenSMOT.

CVPR 2026
@inproceedings{yu2026ego2web,
title={Ego2Web: A Web Agent Benchmark Grounded in Egocentric Videos},
author={Shoubin Yu and Lei Shu and Antoine Yang and Yao Fu and Srinivas Sunkara and Maria Wang and Jindong Chen and Mohit Bansal and Boqing Gong},
booktitle={CVPR},
year={2026}}
Multimodal AI agents are increasingly automating complex real-world workflows that involve online web execution. However, current web-agent benchmarks suffer from a critical limitation: they focus entirely on web-based interaction and perception, lacking grounding in the user's real-world physical surroundings. To address this gap, we introduce Ego2Web, the first benchmark designed to bridge egocentric video perception and web agent execution. Ego2Web pairs real-world first-person video recordings with web tasks that require visual understanding, web task planning, and interaction in an online environment for successful completion. We utilize an automatic data-generation pipeline combined with human verification and refinement to curate well-constructed, high-quality video-task pairs across diverse web task types. We also develop a novel LLM-as-a-Judge automatic evaluation method, Ego2WebJudge, which achieves approximately 84% agreement with human judgment.

Google Blog 2025
@article{comanici2025gemini,
title={Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities},
author={Comanici, Gheorghe and Bieber, Eric and Schaekermann, Mike and Pasupat, Ice and Sachdeva, Noveen and Dhillon, Inderjit and Blistein, Marcel and Ram, Ori and Zhang, Dan and Rosen, Evan and others},
journal={arXiv preprint arXiv:2507.06261},
year={2025}
}
In this report, we introduce the Gemini 2.X model family: Gemini 2.5 Pro and Gemini 2.5 Flash, as well as our earlier Gemini 2.0 Flash and Flash-Lite models. Gemini 2.5 Pro is our most capable model yet, achieving SoTA performance on frontier coding and reasoning benchmarks. In addition to its incredible coding and reasoning skills, Gemini 2.5 Pro is a thinking model that excels at multimodal understanding and it is now able to process up to 3 hours of video content. Its unique combination of long context, multimodal and reasoning capabilities can be combined to unlock new agentic workflows. Gemini 2.5 Flash provides excellent reasoning abilities at a fraction of the compute and latency requirements and Gemini 2.0 Flash and Flash-Lite provide high performance at low latency and cost. Taken together, the Gemini 2.X model generation spans the full Pareto frontier of model capability vs cost, allowing users to explore the boundaries of what is possible with complex agentic problem solving.
CVPR 2025
@inproceedings{ventura2025chapterllama,
title={Chapter-Llama: Efficient Chaptering in Hour-Long Videos with LLMs},
author={Lucas Ventura and Antoine Yang and Cordelia Schmid and G{\"u}l Varol},
booktitle={CVPR},
year={2025}}
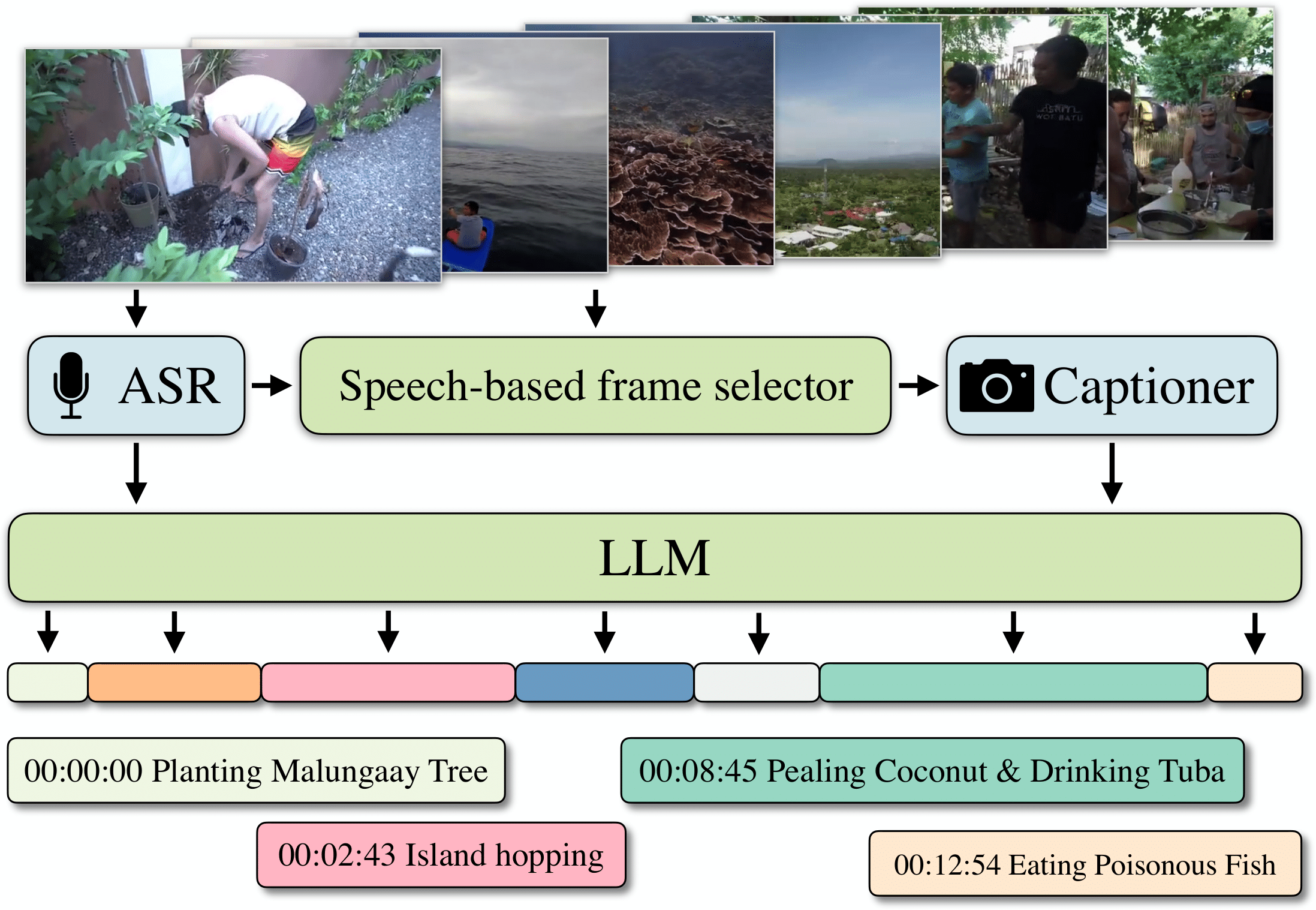
We address the task of video chaptering, i.e., partitioning a long video timeline into semantic units and generating corresponding chapter titles. While relatively underexplored, automatic chaptering has the potential to enable efficient navigation and content retrieval in long-form videos. In this paper, we achieve strong chaptering performance on hour-long videos by efficiently addressing the problem in the text domain with our 'Chapter-Llama' framework. Specifically, we leverage a pretrained large language model (LLM) with large context window, and feed as input (i) speech transcripts and (ii) captions describing video frames, along with their respective timestamps. Given the inefficiency of exhaustively captioning all frames, we propose a lightweight speech-guided frame selection strategy based on speech transcript content, and experimentally demonstrate remarkable advantages. We train the LLM to output timestamps for the chapter boundaries, as well as free-form chapter titles. This simple yet powerful approach scales to processing one-hour long videos in a single forward pass. Our results demonstrate substantial improvements (e.g., 45.3 vs 26.7 F1 score) over the state of the art on the recent VidChapters-7M benchmark. To promote further research, we release our code and models.

Google Blog 2025
@article{team2025gemma,
title={Gemma 3 technical report},
author={Team, Gemma and Kamath, Aishwarya and Ferret, Johan and Pathak, Shreya and Vieillard, Nino and Merhej, Ramona and Perrin, Sarah and Matejovicova, Tatiana and Ram{\'e}, Alexandre and Rivi{\`e}re, Morgane and others},
journal={arXiv preprint arXiv:2503.19786},
year={2025}
}
We introduce Gemma 3, a multimodal addition to the Gemma family of lightweight open models, ranging in scale from 1 to 27 billion parameters. This version introduces vision understanding abilities, a wider coverage of languages and longer context - at least 128K tokens. We also change the architecture of the model to reduce the KV-cache memory that tends to explode with long context. This is achieved by increasing the ratio of local to global attention layers, and keeping the span on local attention short. The Gemma 3 models are trained with distillation and achieve superior performance to Gemma 2 for both pre-trained and instruction finetuned versions. In particular, our novel post-training recipe significantly improves the math, chat, instruction-following and multilingual abilities, making Gemma3-4B-IT competitive with Gemma2-27B-IT and Gemma3-27B-IT comparable to Gemini-1.5-Pro across benchmarks. We release all our models to the community.

Google Blog 2024
@article{reid2024gemini,
title={Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context},
author={Reid, Machel and Savinov, Nikolay and Teplyashin, Denis and Lepikhin, Dmitry and Lillicrap, Timothy and Alayrac, Jean-baptiste and Soricut, Radu and Lazaridou, Angeliki and Firat, Orhan and Schrittwieser, Julian and others},
journal={arXiv preprint arXiv:2403.05530},
year={2024}
}
In this report, we introduce the Gemini 1.5 family of models, representing the next generation of highly compute-efficient multimodal models capable of recalling and reasoning over fine-grained information from millions of tokens of context, including multiple long documents and hours of video and audio. The family includes two new models: (1) an updated Gemini 1.5 Pro, which exceeds the February version on the great majority of capabilities and benchmarks; (2) Gemini 1.5 Flash, a more lightweight variant designed for efficiency with minimal regression in quality. Gemini 1.5 models achieve near-perfect recall on long-context retrieval tasks across modalities, improve the state-of-the-art in long-document QA, long-video QA and long-context ASR, and match or surpass Gemini 1.0 Ultra’s state-of-the-art performance across a broad set of benchmarks. Studying the limits of Gemini 1.5’s long-context ability, we find continued improvement in next-token prediction and near-perfect retrieval (>99%) up to at least 10M tokens, a generational leap over existing models such as Claude 3.0 (200k) and GPT-4 Turbo (128k). Finally, we highlight real-world use cases, such as Gemini 1.5 collaborating with professions on their completing their tasks achieving 26 to 75% time savings across 10 different job categories, as well as surprising new capabilities of large language models at the frontier; when given a grammar manual for Kalamang, a language with fewer than 200 speakers worldwide, the model learns to translate English to Kalamang at a similar level to a person who learned from the same content.
PhD Thesis 2023
@phdthesis{yang:tel-04307117,
TITLE = {{Learning Visual Language Models for Video Understanding}},
AUTHOR = {Yang, Antoine},
URL = {https://hal.science/tel-04307117},
SCHOOL = {{Ecole Normale Superieure de Paris - ENS Paris}},
YEAR = {2023},
MONTH = Nov,
KEYWORDS = {Machine learning ; Computer vision ; Artificial intelligence ; Natural language processing ; Video understanding ; Deep learning ; Apprentissage automatique ; Vision par ordinateur ; Intelligence artificielle ; Traitement du langage naturel ; Compr{\'e}hension de vid{\'e}os ; Apprentissage profond},
TYPE = {Theses},
PDF = {https://hal.science/tel-04307117v2/file/PhD.pdf},
HAL_ID = {tel-04307117},
HAL_VERSION = {v2},
}
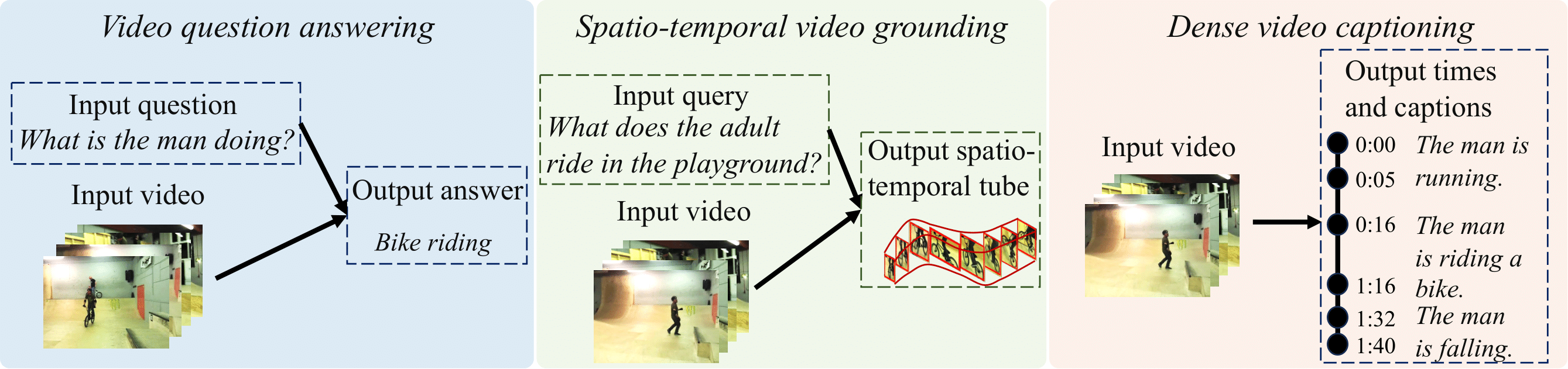
The goal of this thesis is to build and train machine learning models that combine the power of natural language processing with visual understanding, enabling a comprehensive and detailed comprehension of the content within videos. First, we propose two scalable approaches to develop video question answering models without the need for costly manual annotation. We automatically generate video question answering data from narrated videos using text-only question-generation models. We then show that a multi-modal transformer trained contrastively on the generated data can answer visual questions in a zero-shot manner. In order to bypass the data generation procedure, we present an alternative approach, dubbed FrozenBiLM, that directly leverages bidirectional masked language models. Second, we develop TubeDETR, a transformer model that can spatially and temporally localize a natural language query in an untrimmed video. Unlike prior spatio-temporal grounding approaches, TubeDETR can be effectively trained end-to-end on untrimmed videos. Third, we present a new model and a new dataset for multi-event understanding in untrimmed videos. We introduce the Vid2Seq model which generates dense natural language descriptions and corresponding temporal boundaries for all events in an untrimmed video by predicting a single sequence of tokens. Moreover, Vid2Seq can be effectively pretrained on narrated videos at scale using transcribed speech as pseudo-supervision. Finally, we introduce VidChapters-7M, a large-scale dataset of user-chaptered videos. Based on this dataset, we evaluate state-of-the-art models on three tasks including video chapter generation. We also show that video chapter generation models transfer well to dense video captioning in both zero-shot and finetuning settings.

NeurIPS 2023 Track on Datasets and Benchmarks
@inproceedings{yang2023vidchapters,
title={VidChapters-7M: Video Chapters at Scale},
author={Antoine Yang and Arsha Nagrani and Ivan Laptev and Josef Sivic and Cordelia Schmid},
booktitle={NeurIPS},
year = {2023}}
Segmenting long videos into chapters enables users to quickly navigate to the information of their interest. This important topic has been understudied due to the lack of publicly released datasets. To address this issue, we present VidChapters-7M, a dataset of 817K user-chaptered videos including 7M chapters in total. VidChapters-7M is automatically created from videos online in a scalable manner by scraping user-annotated chapters and hence without any additional manual annotation. We introduce the following three tasks based on this data. First, the video chapter generation task consists of temporally segmenting the video and generating a chapter title for each segment. To further dissect the problem, we also define two variants of this task: video chapter generation given ground-truth boundaries, which requires generating a chapter title given an annotated video segment, and video chapter grounding, which requires temporally localizing a chapter given its annotated title. We benchmark both simple baselines and state-of-the-art video-language models for these three tasks. We also show that pretraining on VidChapters-7M transfers well to dense video captioning tasks in both zero-shot and finetuning settings, largely improving the state of the art on the YouCook2 and ViTT benchmarks. Finally, our experiments reveal that downstream performance scales well with the size of the pretraining dataset.

AAAI 2024
Journal extension in TPAMI
@inproceedings{ventura2023covr,
title={CoVR: Learning Composed Video Retrieval from Web Video Captions},
author={Lucas Ventura and Antoine Yang and Cordelia Schmid and G{\"u}l Varol},
booktitle={AAAI},
year={2024}}
@article{ventura2024covr2,
title={CoVR-2: Automatic Data Construction for Composed Video Retrieval},
author={Lucas Ventura and Antoine Yang and Cordelia Schmid and G{\"u}l Varol},
journal={IEEE TPAMI},
year={2024}}
Composed Image Retrieval (CoIR) has recently gained popularity as a task that considers both text and image queries together, to search for relevant images in a database. Most CoIR approaches require manually annotated datasets, containing image-text-image triplets, where the text describes a modification from the query image to the target image. However, manual curation of CoIR triplets is expensive and prevents scalability. In this work, we instead propose a scalable automatic dataset creation methodology that generates triplets given video-caption pairs. To this end, we mine paired videos with a similar caption from a large database, and leverage a large language model to generate the corresponding modification text. We automatically construct our WebVid-CoVR dataset by applying this procedure to the large WebVid2M collection, resulting in 1.6M triplets. Moreover, we introduce a new benchmark for composed video retrieval (CoVR) and contribute a manually annotated evaluation set, along with baseline results. We further show that training a CoVR model on our dataset transfers well to CoIR, improving the state of the art in the zero-shot setup on both the CIRR and FashionIQ benchmarks.

CVPR 2023
@inproceedings{yang2023vid2seq,
title = {Vid2Seq: Large-Scale Pretraining of a Visual Language Model for Dense Video Captioning},
author={Antoine Yang and Arsha Nagrani and Paul Hongsuck Seo and Antoine Miech and Jordi Pont-Tuset and Ivan Laptev and Josef Sivic and Cordelia Schmid},
booktitle={CVPR},
year = {2023}}
In this work, we introduce Vid2Seq, a multi-modal single-stage dense event captioning model pretrained on narrated videos which are readily-available at scale. The Vid2Seq architecture augments a language model with special time tokens, allowing it to seamlessly predict event boundaries and textual descriptions in the same output sequence. Such a unified model requires large-scale training data, which is not available in current annotated datasets. We show that it is possible to leverage unlabeled narrated videos for dense video captioning, by reformulating sentence boundaries of transcribed speech as pseudo event boundaries, and using the transcribed speech sentences as pseudo event captions. The resulting Vid2Seq model pretrained on the YT-Temporal-1B dataset improves the state of the art on a variety of dense video captioning benchmarks including YouCook2, ViTT and ActivityNet Captions. Vid2Seq also generalizes well to the tasks of video paragraph captioning and video clip captioning, and to few-shot settings.
NeurIPS 2022
@inproceedings{yang2022frozenbilm,
title = {Zero-Shot Video Question Answering via Frozen Bidirectional Language Models},
author={Antoine Yang and Antoine Miech and Josef Sivic and Ivan Laptev and Cordelia Schmid},
booktitle={NeurIPS}
year = {2022}}
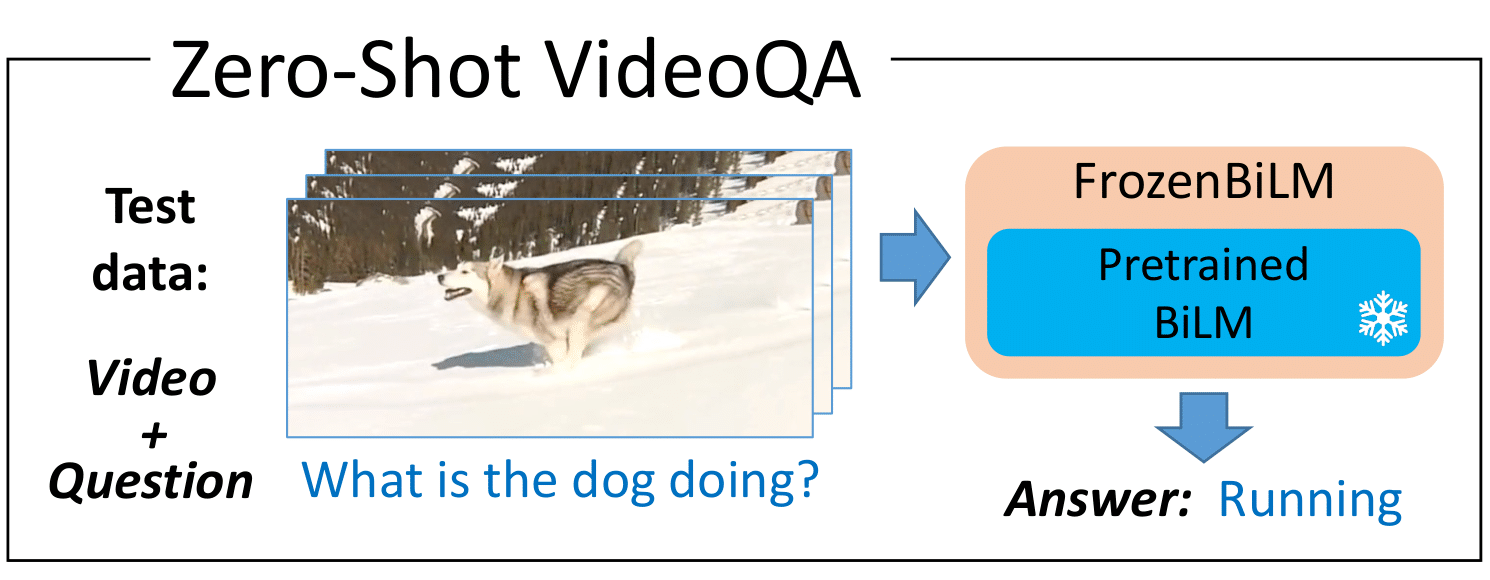
Video question answering (VideoQA) is a complex task that requires diverse multi-modal data for training. Manual annotation of question and answers for videos, however, is tedious and prohibits scalability. To tackle this problem, recent methods consider zero-shot settings with no manual annotation of visual question-answer. In particular, a promising approach adapts frozen autoregressive language models pretrained on Web-scale text-only data to multi-modal inputs. In contrast, we here build on frozen bidirectional language models (BiLM) and show that such an approach provides a stronger and cheaper alternative for zero-shot VideoQA. In particular, (i) we combine visual inputs with the frozen BiLM using light trainable modules, (ii) we train such modules using Web-scraped multi-modal data, and finally (iii) we perform zero-shot VideoQA inference through masked language modeling, where the masked text is the answer to a given question. Our proposed approach, FrozenBiLM, outperforms the state of the art in zero-shot VideoQA by a significant margin on a variety of datasets, including LSMDC-FiB, iVQA, MSRVTT-QA, MSVD-QA, ActivityNet-QA, TGIF-FrameQA, How2QA and TVQA. It also demonstrates competitive performance in the few-shot and fully-supervised setting.

CVPR 2022 (oral: top 4% submissions)
@inproceedings{yang2022tubedetr,
author={Antoine Yang and Antoine Miech and Josef Sivic and Ivan Laptev and Cordelia Schmid},
title={TubeDETR: Spatio-Temporal Video Grounding With Transformers},
booktitle={CVPR},
year={2022}}
We consider the problem of localizing a spatio-temporal tube in a video corresponding to a given text query. This is a challenging task that requires the joint and efficient modeling of temporal, spatial and multi-modal interactions. To address this task, we propose TubeDETR, a transformer-based architecture inspired by the recent success of such models for text-conditioned object detection. Our model notably includes: (i) an efficient video and text encoder that models spatial multi-modal interactions over sparsely sampled frames and (ii) a space-time decoder that jointly performs spatio-temporal localization. We demonstrate the advantage of our proposed components through an extensive ablation study. We also evaluate our full approach on the spatio-temporal video grounding task and demonstrate improvements over the state of the art on the challenging VidSTG and HC-STVG benchmarks.

ICCV 2021 (oral: top 3% submissions)
Journal extension in TPAMI Special Issue of the Best Papers of 2021
@inproceedings{yang2021justask,
title={Just Ask: Learning To Answer Questions From Millions of Narrated Videos},
author={Antoine Yang and Antoine Miech and Josef Sivic and Ivan Laptev and Cordelia Schmid},
booktitle={ICCV},
year={2021}}
@article{yang2022learningta,
title={Learning to Answer Visual Questions from Web Videos},
author={Antoine Yang and Antoine Miech and Josef Sivic and Ivan Laptev and Cordelia Schmid},
journal={IEEE TPAMI},
year={2022}}
Recent methods for visual question answering rely on large-scale annotated datasets. Manual annotation of questions and answers for videos, however, is tedious, expensive and prevents scalability. In this work, we propose to avoid manual annotation and generate a large-scale training dataset for video question answering making use of automatic cross-modal supervision. We leverage a question generation transformer trained on text data and use it to generate question-answer pairs from transcribed video narrations. Given narrated videos, we then automatically generate the HowToVQA69M dataset with 69M video-question-answer triplets. To handle the open vocabulary of diverse answers in this dataset, we propose a training procedure based on a contrastive loss between a video-question multi-modal transformer and an answer transformer. We introduce the zero-shot VideoQA task and show excellent results, in particular for rare answers. Furthermore, we demonstrate our method to significantly outperform the state of the art on MSRVTT-QA, MSVD-QA, ActivityNet-QA and How2QA. Finally, for a detailed evaluation we introduce iVQA, a new VideoQA dataset with reduced language biases and high-quality redundant manual annotations.
Antoine Yang, Pedro M. Esperança, Fabio Maria Carlucci
ICLR 2020
@inproceedings{yang2020nasefh,
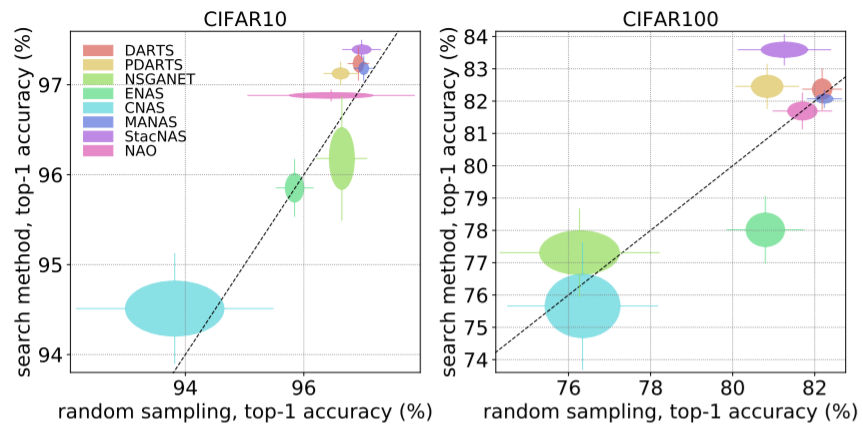
title={NAS evaluation is frustratingly hard},
author={Antoine Yang and Pedro M. Esperança and Fabio M. Carlucci},
booktitle={ICLR},
year={2020}}
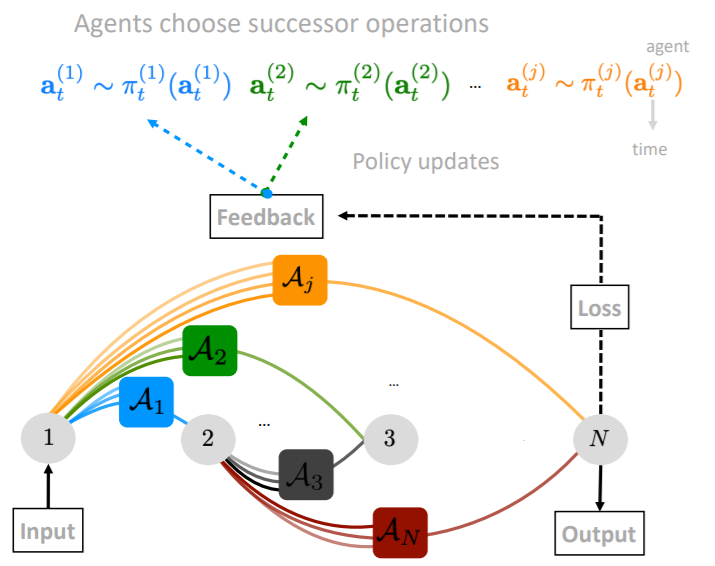
Vasco Lopes, Fabio Maria Carlucci, Pedro M. Esperança, Marco Singh, Antoine Yang, Victor Gabillon, Hang Xu, Zewei Chen, Jun Wang
Machine Learning 2023
@article{lopes2023manas,
title={MANAS: Multi-Agent Neural Architecture Search},
author={Lopes Vasco and Fabio Maria Carlucci and Pedro M Esperan{\c{c}}a and Marco Singh and Antoine Yang and Victor Gabillon and Hang Xu and Zewei Chen and Jun Wang},
journal={Machine Learning},
year={2023}}
Talks
- 04/2024 - Seminar of the Visual Geometry Group at University of Oxford, Talk (Oxford, United Kingdom) - Vid2Seq and VidChapters-7M projects - [Slides]
- 03/2024 - Seminar of the Digital Environment Research Institute at Queen Mary University of London, 20-min Talk (Virtual) - Vid2Seq and VidChapters-7M projects - [Slides]
- 01/2024 - BMVA Symposium on Vision and Language, Poster Session (London, United Kingdom) - VidChapters-7M project - [Poster]
- 12/2023 - NeurIPS 2023, Poster Session (New Orleans, Louisiana) - VidChapters-7M project - [5 min Video] - [Slides] - [Poster]
- 11/2023 - The AI Talks, 45-min Talk (Virtual) - VLM for video understanding - [Recording]
- 11/2023 - ENS PhD Defense, 45-min Presentation (Paris, France) - VLM for video understanding - [Slides]
- 10/2023 - HCERES visit, Poster Session (Paris, France) - VidChapters-7M project - [Poster]
- 10/2023 - ICCV 2023 Doctoral Consortium, 15-min Discussion (Paris, France) - VidChapters-7M project - [Slides]
- 07/2023 - ICVSS 2023, Poster Session (Sampieri, Italy) - Vid2Seq project - [Poster]
- 07/2023 - Imagine ENPC Seminar (Champs-sur-Marne, France), 1-min Highlight - Vid2Seq project
- 06/2023 - CVPR 2023, Poster Session (Vancouver, British Columbia) - Vid2Seq project - [8 min Video] - [Slides] - [Poster]
- 05/2023 - ELLIS computer vision workshop, Spotlight and Poster Session (Metzingen, Germany) - Vid2Seq project - [Poster]
- 02/2023 - Google Perception Spotlights, 5-min Talk (Virtual) - Vid2Seq project
- 01/2023 - PRAIRIE workshop, Poster Session (Paris, France) - FrozenBiLM project - [Poster]
- 11/2022 - NeurIPS 2022, Poster Session (New Orleans, Louisiana) - FrozenBiLM project - [5 min Video] - [Slides] - [Poster]
- 11/2022 - NeurIPS@Paris 2022, 6-min Talk (Paris, France) - FrozenBiLM project - [Slides] - [Poster]
- 10/2022 - Seminar of Inria Willow and Sierra teams, Poster Session (Saint-Raphaël, France) - FrozenBiLM project - [Poster]
- 06/2022 - CVPR 2022, Oral and Poster Session (New Orleans, Louisiana) - TubeDETR project - [5 min Video] - [Slides] - [Poster]
- 06/2022 - Seminar of the Computer Science department of École Normale Supérieure, 15-min Talk (Mûr-de-Bretagne, France) - FrozenBiLM project - [Slides]
- 10/2021 - Seminar of Inria Willow and Sierra teams, Poster Session (Avignon, France) - Just Ask project - [Poster]
- 10/2021 - ICCV 2021, Oral and Poster Session (Virtual) - Just Ask project - [12 min Video] - [Slides] - [Poster]
- 06/2021 - CVPR 2021 Holistic Video Understanding Workshop, 10-min Invited Talk (Virtual) - Just Ask project - [Slides] - [Recording]
- 05/2021 - Inria Junior Seminar, 30-min Talk (Virtual) - Just Ask project - [Slides] - [Recording]
- 09/2020 - MVA Master Defense, Inria Internship 20-min Presentation (Paris, France) - Video Question Answering
- 04/2020 - ICLR 2020, Poster Session (Virtual) - NAS evaluation project - [5 min Video] - [Slides]
- 09/2019 - Ecole Polytechnique Master Defense, Huawei Internship 40-min Presentation (Palaiseau, France) - NAS evaluation project
Teaching
Misc.
I am a reviewer for CVPR 2022, ECCV 2022, CVPR 2023, IJCV 2023, ICCV 2023, TPAMI 2023, NeurIPS 2023, ICML 2024, ICLR 2025, CVPR 2026 and ECCV 2026.
Besides research, my passions include running, hiking and travels.