Vid2Seq: Large-Scale Pretraining of a Visual Language Model for Dense Video Captioning
Abstract
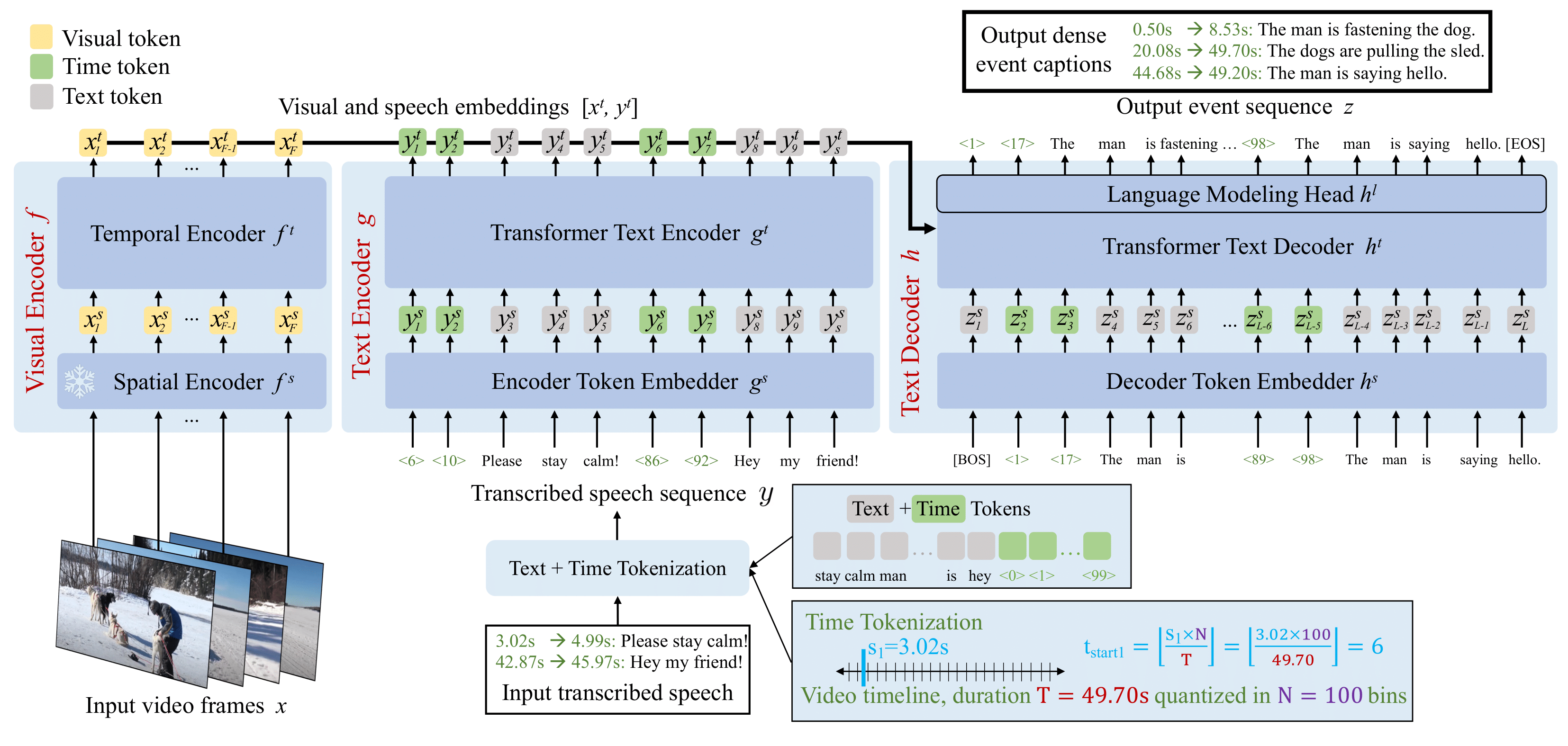
In this work, we introduce Vid2Seq, a multi-modal single-stage dense event captioning model pretrained on narrated videos which are readily-available at scale. The Vid2Seq architecture augments a language model with special time tokens, allowing it to seamlessly predict event boundaries and textual descriptions in the same output sequence. Such a unified model requires large-scale training data, which is not available in current annotated datasets. We show that it is possible to leverage unlabeled narrated videos for dense video captioning, by reformulating sentence boundaries of transcribed speech as pseudo event boundaries, and using the transcribed speech sentences as pseudo event captions. The resulting Vid2Seq model pretrained on the YT-Temporal-1B dataset improves the state of the art on a variety of dense video captioning benchmarks including YouCook2, ViTT and ActivityNet Captions. Vid2Seq also generalizes well to the tasks of video paragraph captioning and video clip captioning, and to few-shot settings.
Video: 8 min presentation
Video: extra results
Paper
BibTeX
@inproceedings{yang2023vid2seq,
title = {Vid2Seq: Large-Scale Pretraining of a Visual Language Model for Dense Video Captioning},
author={Antoine Yang and Arsha Nagrani and Paul Hongsuck Seo and Antoine Miech and Jordi Pont-Tuset and Ivan Laptev and Josef Sivic and Cordelia Schmid},
booktitle={CVPR},
year = {2023}}
Code and models
Misc.
People
 Antoine Yang |
 Arsha Nagrani |
 Paul Hongsuck Seo |
 Antoine Miech |
 Jordi Pont-Tuset |
 Ivan Laptev |
 Josef Sivic |
 Cordelia Schmid |
Acknowledgements
The work was partially funded by a Google gift, the French government under management of Agence Nationale de la Recherche as part of the "Investissements d'avenir" program, reference ANR-19-P3IA-0001 (PRAIRIE 3IA Institute), the Louis Vuitton ENS Chair on Artificial Intelligence, the European Regional Development Fund under project IMPACT (reg.\ no.\ CZ.02.1.01/0.0/0.0/15 003/0000468).
We thank Anurag Arnab, Minsu Cho, Anja Hauth, Ashish Thapliyal, Bo Pang, Bryan Seybold and the entire Ganesha team for helpful discussions.
Copyright Notice
The documents contained in these directories are included by the contributing authors as a means to ensure timely dissemination of scholarly and technical work on a non-commercial basis. Copyright and all rights therein are maintained by the authors or by other copyright holders, notwithstanding that they have offered their works here electronically. It is understood that all persons copying this information will adhere to the terms and constraints invoked by each author's copyright.




