Just Ask: Learning to Answer Questions from Millions of Narrated Videos
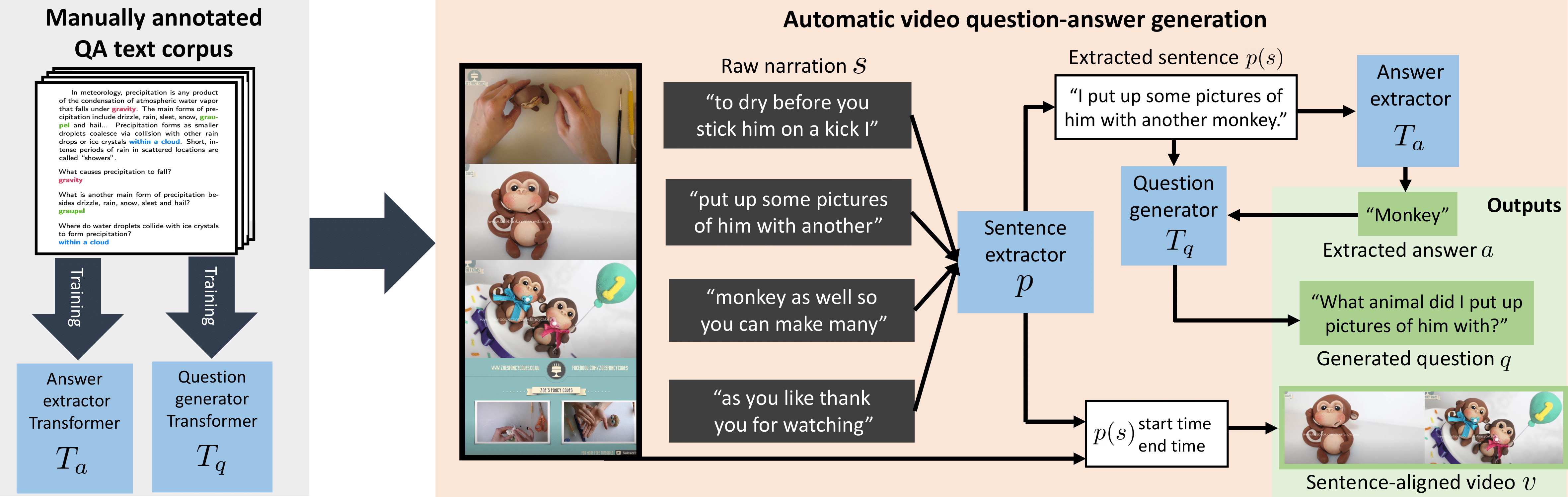
Abstract
Recent methods for visual question answering rely on large-scale annotated datasets. Manual annotation of questions and answers for videos, however, is tedious, expensive and prevents scalability. In this work, we propose to avoid manual annotation and generate a large-scale training dataset for video question answering making use of automatic cross-modal supervision. We leverage a question generation transformer trained on text data and use it to generate question-answer pairs from transcribed video narrations. Given narrated videos, we then automatically generate the HowToVQA69M dataset with 69M video-question-answer triplets. To handle the open vocabulary of diverse answers in this dataset, we propose a training procedure based on a contrastive loss between a video-question multi-modal transformer and an answer transformer. We introduce the zero-shot VideoQA task and show excellent results, in particular for rare answers. Furthermore, we demonstrate our method to significantly outperform the state of the art on MSRVTT-QA, MSVD-QA, ActivityNet-QA and How2QA. Finally, for a detailed evaluation we introduce iVQA, a new VideoQA dataset with reduced language biases and high-quality redundant manual annotations.
Online VideoQA Demo
At this link, we host an online demo where you can ask the question of your choice to our models about a large set of videos. Here is an example below:Video: 2 min presentation
Video: 12 min presentation
Video: extra results
Conference Paper
- arXiv
- HAL
- ICCV 2021 Proceedings: CVF; IEEE Xplore
BibTeX
@inproceedings{yang2021justask,
title={Just Ask: Learning To Answer Questions From Millions of Narrated Videos},
author={Antoine Yang and Antoine Miech and Josef Sivic and Ivan Laptev and Cordelia Schmid},
booktitle={ICCV},
year={2021}}
Journal Extension (Learning to Answer Visual Questions from Web Videos)
- arXiv
- HAL
- TPAMI Special Issue on the Best Papers of ICCV 2021: IEEE preprint
BibTeX
@article{yang2022learningta,
title={Learning to Answer Visual Questions from Web Videos},
author={Antoine Yang and Antoine Miech and Josef Sivic and Ivan Laptev and Cordelia Schmid},
journal={IEEE TPAMI},
year={2022}}
Code
iVQA Data
- iVQA annotations and features
- iVQA form to download raw videos
- For a quick overview, you can visualize examples of annotations in the video of extra results or in the Online VideoQA Demo .
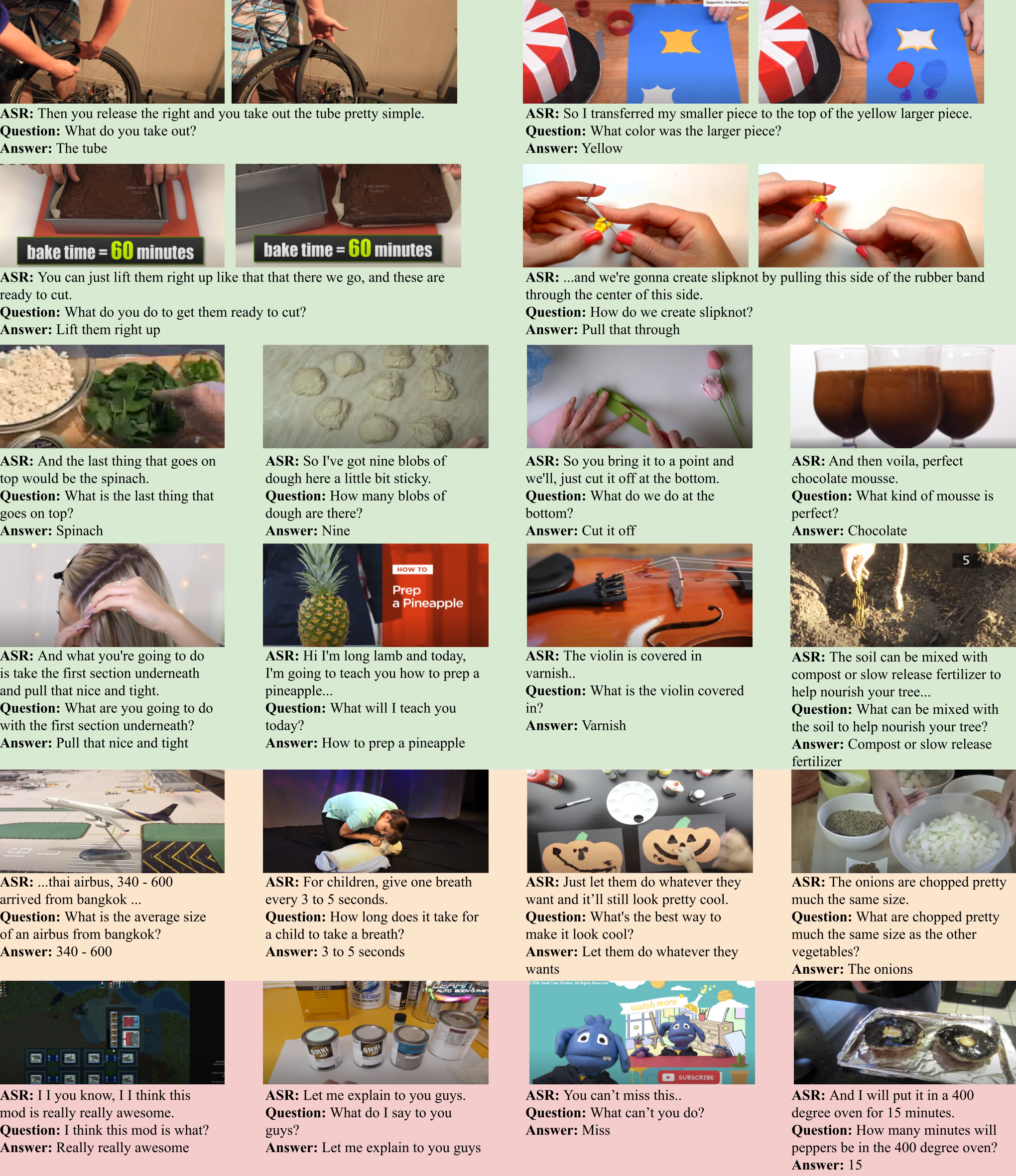
HowToVQA69M Data
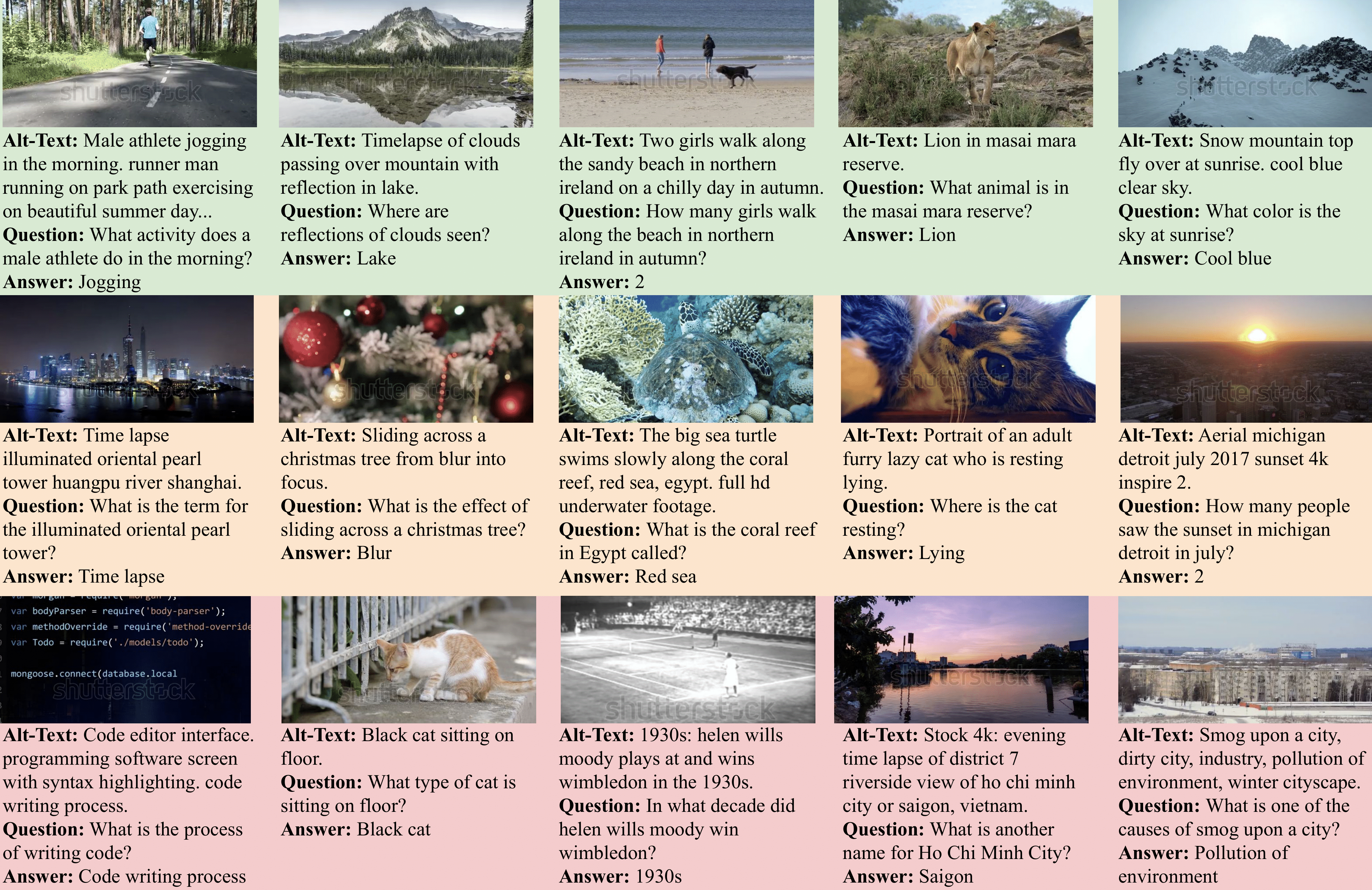
WebVidVQA3M Data
Disclaimer
Data sourced from YouTube or Shutterstock may be prone to biases. Please be careful of unintended societal, gender, racial and other biases when training or deploying models trained on this data.Misc.





Acknowledgements
This work was granted access to the HPC resources of IDRIS under the allocation 2020-101267 made by GENCI.
This work was funded by a Google gift, the French government under management of Agence Nationale de la Recherche as part of the "Investissements d'avenir" program, reference ANR-19-P3IA-0001 (PRAIRIE 3IA Institute), the Louis Vuitton ENS Chair on Artificial Intelligence, the European Regional Development Fund under project IMPACT (reg. no. CZ.02.1.01/0.0/0.0/15 003/0000468) and Antoine Miech's Google PhD fellowship.
We thank Pierre-Louis Guhur and Makarand Tapaswi for advices on using Amazon Mechanical Turk, Eloïse Berthier, Quentin Le Lidec and Elliot Chane-Sane for manual evaluation of a sample of generated data, and Ignacio Rocco for proofreading.
Copyright Notice
The documents contained in these directories are included by the contributing authors as a means to ensure timely dissemination of scholarly and technical work on a non-commercial basis. Copyright and all rights therein are maintained by the authors or by other copyright holders, notwithstanding that they have offered their works here electronically. It is understood that all persons copying this information will adhere to the terms and constraints invoked by each author's copyright.



