TubeDETR: Spatio-Temporal Video Grounding with Transformers
Abstract
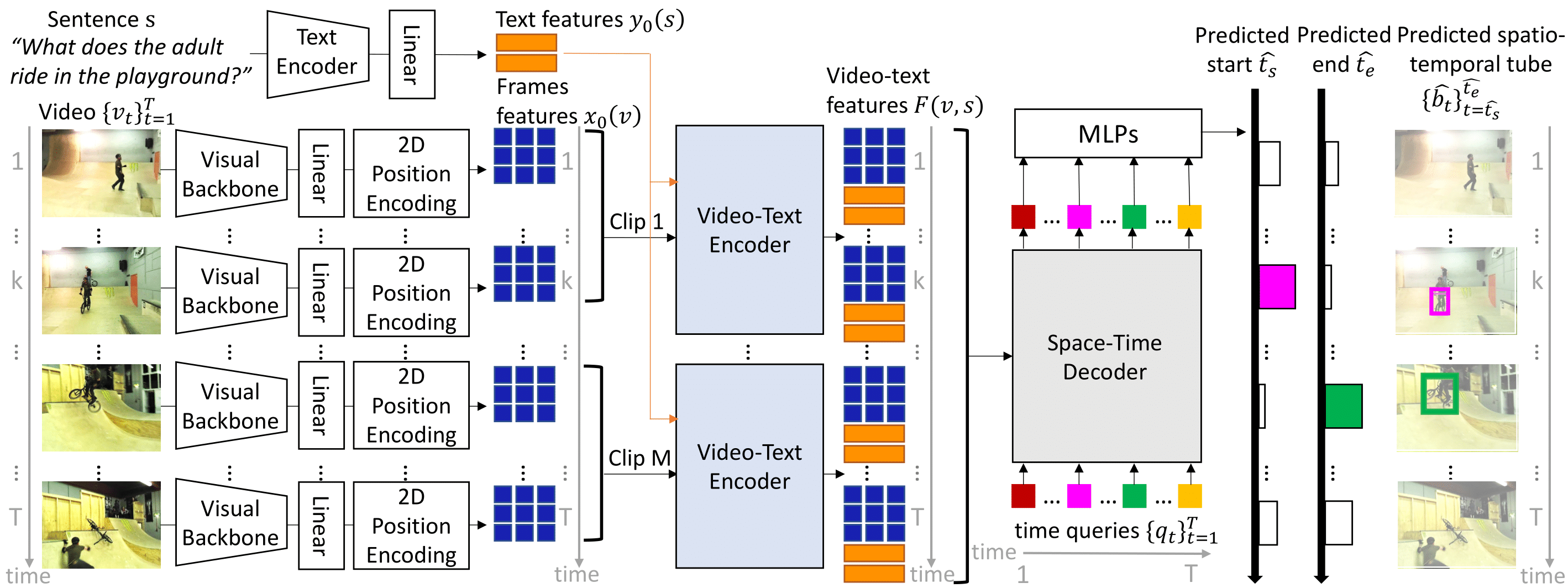
We consider the problem of localizing a spatio-temporal tube in a video corresponding to a given text query. This is a challenging task that requires the joint and efficient modeling of temporal, spatial and multi-modal interactions. To address this task, we propose TubeDETR, a transformer-based architecture inspired by the recent success of such models for text-conditioned object detection. Our model notably includes: (i) an efficient video and text encoder that models spatial multi-modal interactions over sparsely sampled frames and (ii) a space-time decoder that jointly performs spatio-temporal localization. We demonstrate the advantage of our proposed components through an extensive ablation study. We also evaluate our full approach on the spatio-temporal video grounding task and demonstrate improvements over the state of the art on the challenging VidSTG and HC-STVG benchmarks.
Online Spatio-Temporal Video Grounding Demo
At this link, we host an online demo where you can localize spatio-temporally the (declarative or interrogative) natural language query of your choice with our model on a large set of videos. Here is an example below:Video: 5 min presentation
Video: extra results
Paper
- arXiv
- HAL
- CVPR 2022 Proceedings: CVF; IEEE Xplore. Note that vIoU results in the arXiv and the HAL versions are updated compared to this version.
BibTeX
@inproceedings{yang2022tubedetr,
author={Antoine Yang and Antoine Miech and Josef Sivic and Ivan Laptev and Cordelia Schmid},
title={TubeDETR: Spatio-Temporal Video Grounding With Transformers},
booktitle={CVPR},
year={2022}}
Code





Acknowledgements
This work was granted access to the HPC resources of IDRIS under the allocation 2021-AD011011670R1 made by GENCI.
The work was funded by a Google gift, the French government under management of Agence Nationale de la Recherche as part of the "Investissements d'avenir" program, reference ANR-19-P3IA-0001 (PRAIRIE 3IA Institute), the Louis Vuitton ENS Chair on Artificial Intelligence, the European Regional Development Fund under project IMPACT (reg.\ no.\ CZ.02.1.01/0.0/0.0/15 003/0000468).
We thank S. Chen and J. Chen for helpful discussions and O. Bounou and P.-L. Guhur for proofreading.
Copyright Notice
The documents contained in these directories are included by the contributing authors as a means to ensure timely dissemination of scholarly and technical work on a non-commercial basis. Copyright and all rights therein are maintained by the authors or by other copyright holders, notwithstanding that they have offered their works here electronically. It is understood that all persons copying this information will adhere to the terms and constraints invoked by each author's copyright.



