Zero-Shot Video Question Answering via Frozen Bidirectional Language Models
Abstract
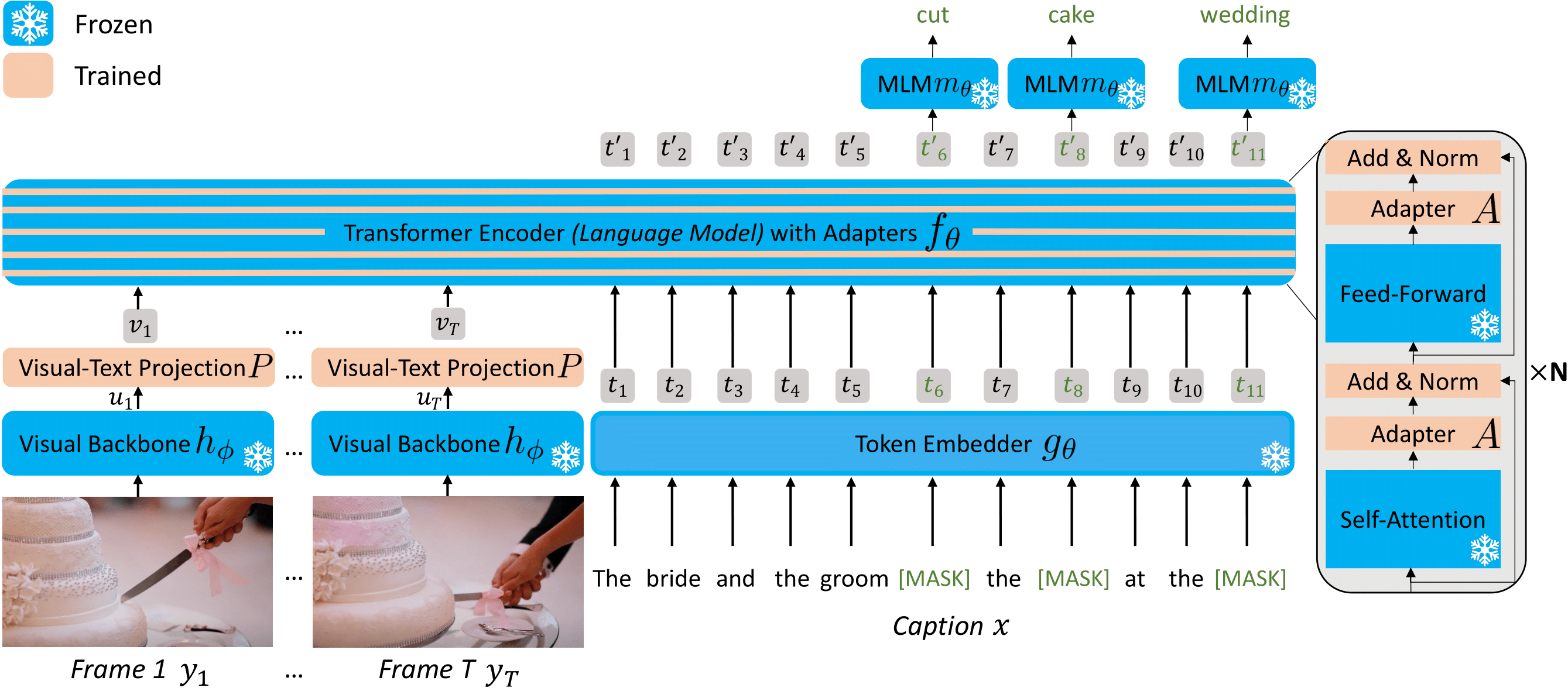
Video question answering (VideoQA) is a complex task that requires diverse multi-modal data for training. Manual annotation of question and answers for videos, however, is tedious and prohibits scalability. To tackle this problem, recent methods consider zero-shot settings with no manual annotation of visual question-answer. In particular, a promising approach adapts frozen autoregressive language models pretrained on Web-scale text-only data to multi-modal inputs. In contrast, we here build on frozen bidirectional language models (BiLM) and show that such an approach provides a stronger and cheaper alternative for zero-shot VideoQA. In particular, (i) we combine visual inputs with the frozen BiLM using light trainable modules, (ii) we train such modules using Web-scraped multi-modal data, and finally (iii) we perform zero-shot VideoQA inference through masked language modeling, where the masked text is the answer to a given question. Our proposed approach, FrozenBiLM, outperforms the state of the art in zero-shot VideoQA by a significant margin on a variety of datasets, including LSMDC-FiB, iVQA, MSRVTT-QA, MSVD-QA, ActivityNet-QA, TGIF-FrameQA, How2QA and TVQA. It also demonstrates competitive performance in the few-shot and fully-supervised setting.
Video: 5 min presentation
Video: extra results
Paper
BibTeX
@inproceedings{yang2022frozenbilm,
title = {Zero-Shot Video Question Answering via Frozen Bidirectional Language Models},
author={Antoine Yang and Antoine Miech and Josef Sivic and Ivan Laptev and Cordelia Schmid},
booktitle={NeurIPS}
year = {2022}}





Acknowledgements
This work was granted access to the HPC resources of IDRIS under the allocation 2022-AD011011670R2 made by GENCI.
The work was funded by a Google gift, the French government under management of Agence Nationale de la Recherche as part of the "Investissements d'avenir" program, reference ANR-19-P3IA-0001 (PRAIRIE 3IA Institute), the Louis Vuitton ENS Chair on Artificial Intelligence, the European Regional Development Fund under project IMPACT (reg.\ no.\ CZ.02.1.01/0.0/0.0/15 003/0000468).
We thank anonymous reviewers for giving interesting feedback.
We thank Gaspard Beugnot, Clémence Bouvier and Pierre-Louis Guhur for proofreading.
Copyright Notice
The documents contained in these directories are included by the contributing authors as a means to ensure timely dissemination of scholarly and technical work on a non-commercial basis. Copyright and all rights therein are maintained by the authors or by other copyright holders, notwithstanding that they have offered their works here electronically. It is understood that all persons copying this information will adhere to the terms and constraints invoked by each author's copyright.



