VidChapters-7M: Video Chapters at Scale

Abstract
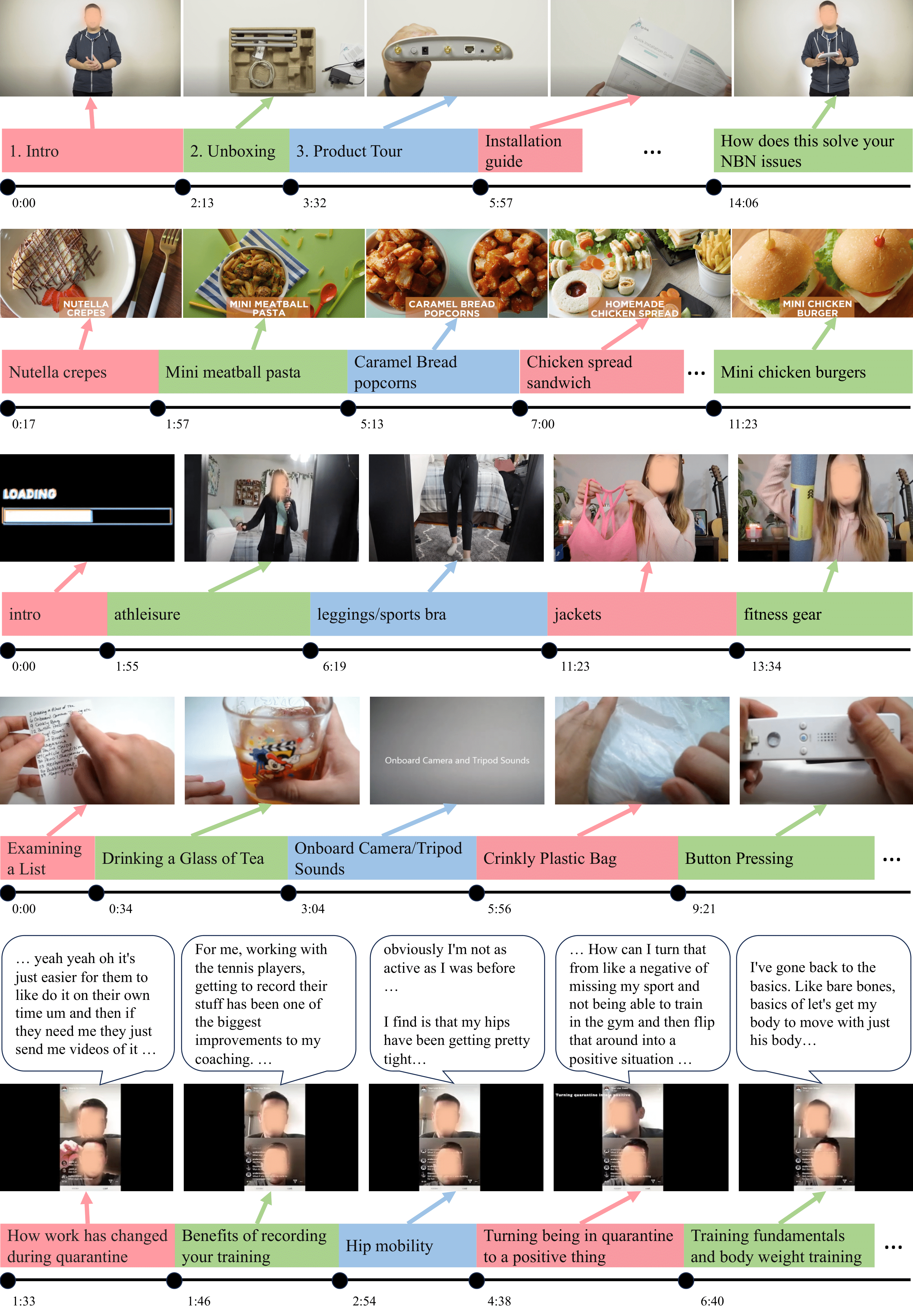
Segmenting long videos into chapters enables users to quickly navigate to the information of their interest. This important topic has been understudied due to the lack of publicly released datasets. To address this issue, we present VidChapters-7M, a dataset of 817K user-chaptered videos including 7M chapters in total. VidChapters-7M is automatically created from videos online in a scalable manner by scraping user-annotated chapters and hence without any additional manual annotation. We introduce the following three tasks based on this data. First, the video chapter generation task consists of temporally segmenting the video and generating a chapter title for each segment. To further dissect the problem, we also define two variants of this task: video chapter generation given ground-truth boundaries, which requires generating a chapter title given an annotated video segment, and video chapter grounding, which requires temporally localizing a chapter given its annotated title. We benchmark both simple baselines and state-of-the-art video-language models for these three tasks. We also show that pretraining on VidChapters-7M transfers well to dense video captioning tasks in both zero-shot and finetuning settings, largely improving the state of the art on the YouCook2 and ViTT benchmarks. Finally, our experiments reveal that downstream performance scales well with the size of the pretraining dataset.
Video: 5 min presentation
Paper
BibTeX
@inproceedings{yang2023vidchapters,
title={VidChapters-7M: Video Chapters at Scale},
author={Antoine Yang and Arsha Nagrani and Ivan Laptev and Josef Sivic and Cordelia Schmid},
booktitle={NeurIPS},
year = {2023}}
Code and models
VidChapters-7M Dataset
- Annotations
- ASR
- Training/Validation/Testing video IDs
- Tagged video IDs
- Problematic video removal request form
Disclaimer
Data sourced from YouTube may be prone to biases. Please be careful of unintended societal, gender, racial and other biases when training or deploying models trained on this data.




Acknowledgements
This work was granted access to the HPC resources of IDRIS under the allocation 2023-A0131011670 made by GENCI.
The work was funded by Antoine Yang's Google PhD fellowship, the French government under management of Agence Nationale de la Recherche as part of the "Investissements d'avenir" program, reference ANR-19-P3IA-0001 (PRAIRIE 3IA Institute), the Louis Vuitton ENS Chair on Artificial Intelligence, the European Regional Development Fund under project IMPACT (reg.\ no.\ CZ.02.1.01/0.0/0.0/15 003/0000468).
We thank Jack Hessel and Rémi Lacroix for helping with forming the dataset, and Antoine Miech for interesting discussions.
Copyright Notice
The documents contained in these directories are included by the contributing authors as a means to ensure timely dissemination of scholarly and technical work on a non-commercial basis. Copyright and all rights therein are maintained by the authors or by other copyright holders, notwithstanding that they have offered their works here electronically. It is understood that all persons copying this information will adhere to the terms and constraints invoked by each author's copyright.


